
UpDown Dev Story
아파치 카프카 for beginners 수강후기 본문
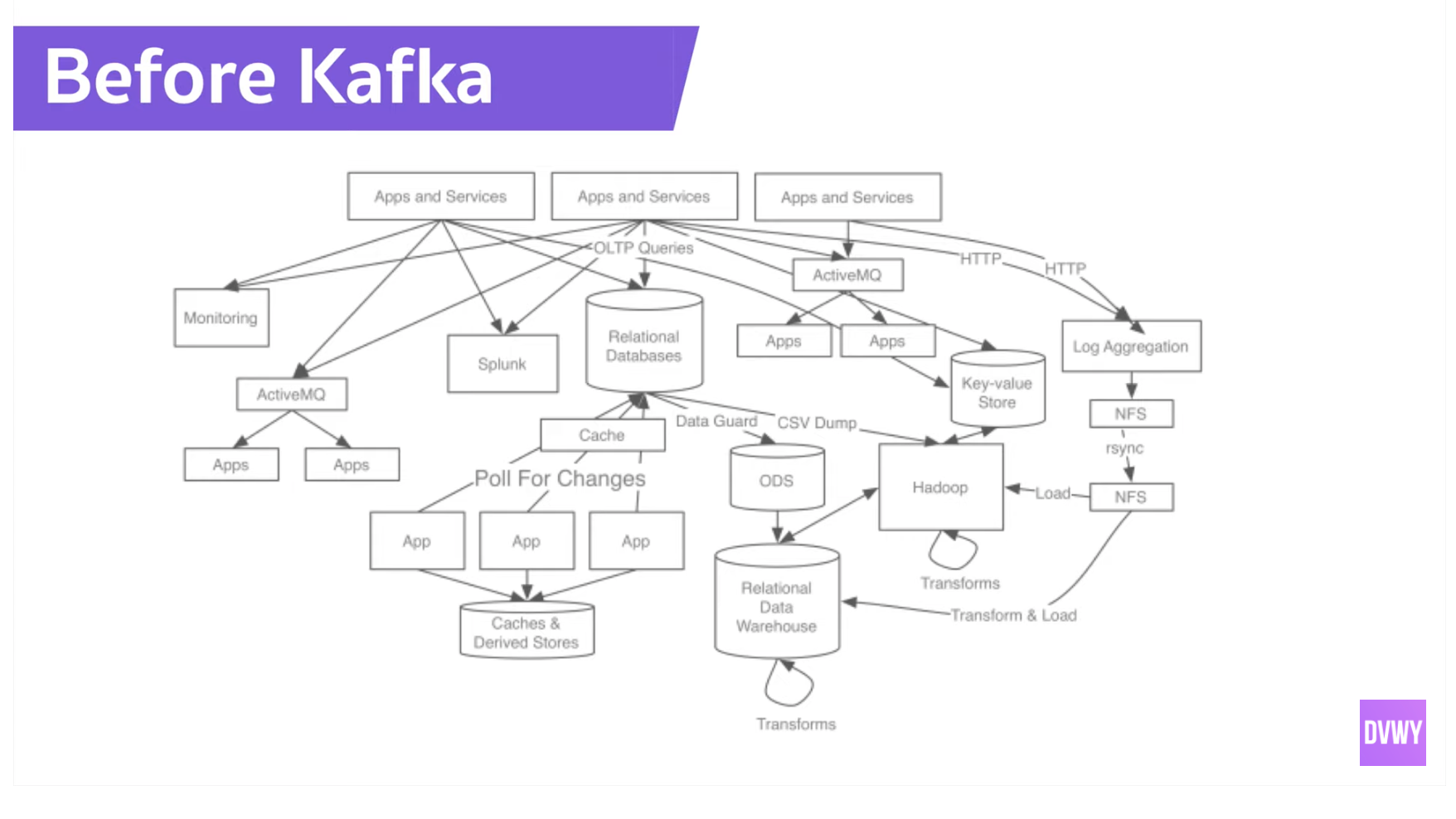
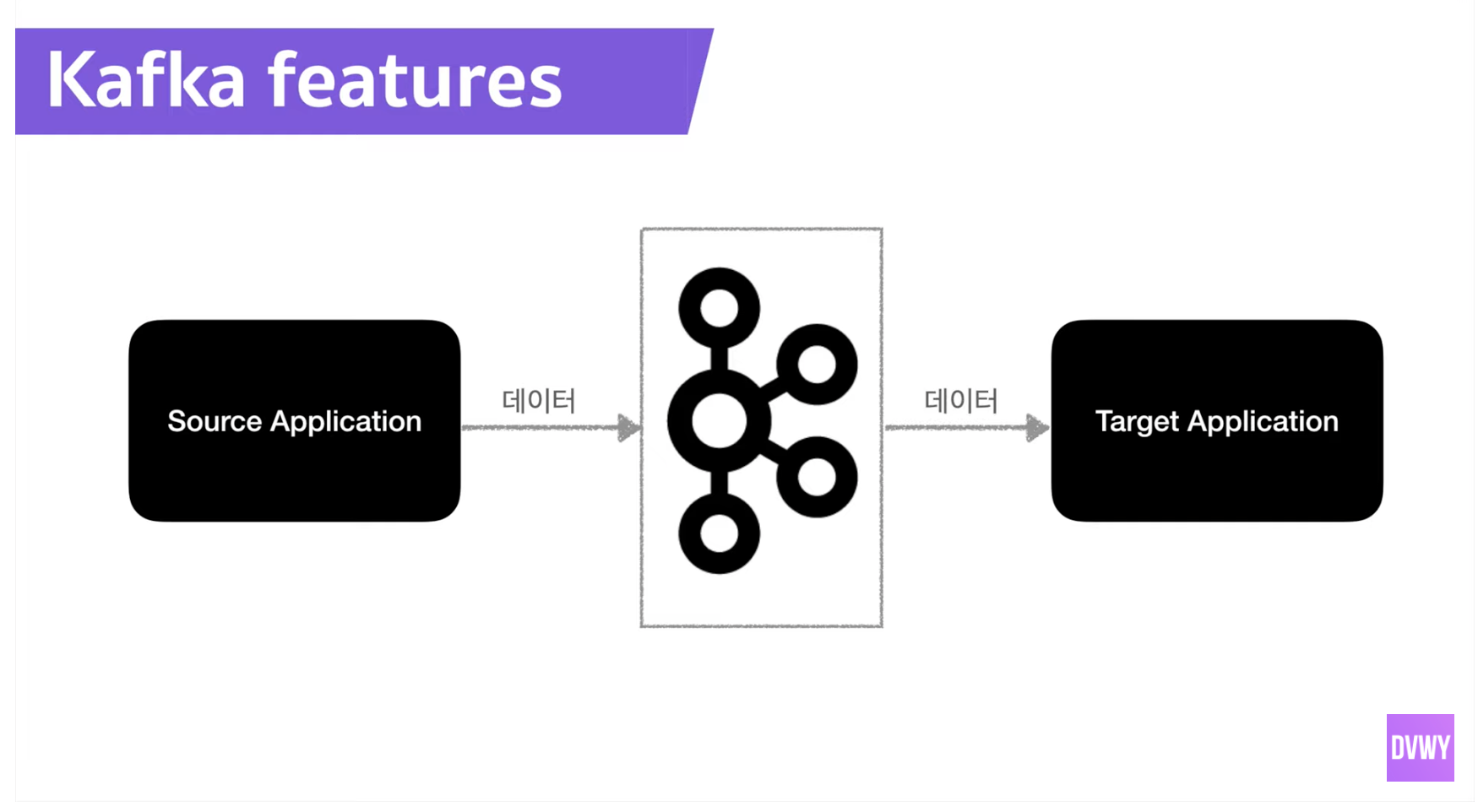
- 카프카는 왜 만들어졌고 왜 사용되는가?
- 카프카는 링크드인에서 만들었다
- 카프카는 데이터처리를 각각 다른 애플리케이션에서 하는게 아니고 카프카에 집결시켜서 사용할 수 있다
- 카프카는 짧은 시간내에 많은양의 데이터를 처리 가능하다 (파티션을 나눠서 병렬처리를 더 빠르게 가능하다)
- 카프카는 확장성이 뛰어나다 이미 사용하고 있는 브로커가 있더라도 운영중에 브로커를 늘려서 확장시킬수 있고 복제를 통해 고 가용성도 보장된다
- 컨슈머가 데이터를 가져가더라도 데이터가 사라지지 않는다(여러 시스템에서 동일한 데이터를 다룰수 있다)
- 카프카의 특징
- 낮은 지연과 높은 처리량을 가지고 있다
- 데이터를 토픽에 보내는건 프로듀싱 받는건 컨슈밍이라고 한다
- 토픽이란?
- 토픽은 여러개 생성 할 수 있다
- 토픽안에 파티션에 데이터를 넣는건 프로듀서
- 토픽안에 파티션에 데이터를 가져오는건 컨슈머라고한다
- 하나의 토픽은 여러개의 파티션으로 구성될 수 있다
- 파티션은 0번부터 시작하게된다
- 컨슈밍을 하게되면 가장 오래된 순서부터 데이터를 가져오게된다
- 컨슈머가 토픽에 데이터를 가져가도 데이터는 삭제되지 않음
- 다른 컨슈머가 붙었을 경우 삭제되지 않은 데이터는 다시 0번부터 가져가서 사용할 수 있다
(다만 auto.offset.reset=earliest 여야하고, 컨슈머 그룹이 달라야한다) - 이를 이용해 동일데이터를 두 번 사용할 수 있다.
- 파티션이 2개 이상인 경우 라운드로빈(하나씩 번갈아가며)으로 들어간다
- 브로커, 복제, ISR
- 브로커란
- 보통 카프카가 설치되어 있는 서버 단위를 말한다
- 보통 3개 이상의 브로커로 구성하는것을 권장한다
- 복제란
- 고 가용성을 위해 사용(오랜기간 운영할 수 있는 성질)
- 3개 중 하나는 리더파티션이고 나머지 2개는 팔로워 파티션이라고 한다
- 이 3개를 합쳐서 ISR(In Sync Replica)라고 부를수 있다.
- 프로듀서에는 ack라는 상세 옵션이 있다
- 0 프로듀서는 리더 파티션에 데이터를 전송하고 응답값은 전달받지 않음(속도빠름)
- 1 리더 파티션에 데이터를 전송하고 응답값도 전달받음 (복제까지 됐는지는 확인안함)
- all 리더파티션에 데이터를 전송하고 리더파티션과 팔로워 파티션에 복제까지 정상적으로 됐는지까지 확인(속도 느림)
- 브로커란
- 파티셔녀
- 프로듀서가 데이터를 보내면 파티셔너를 통해서 브로커로 데이터가 전송된다
- 파티셔너는 데이터를 토픽에 어떤 파티션에 넣을지 결정하는 역할을 한다
- 레코드에 포함된 메시지 키 또는 메시지 값에 따라서 파티션의 위치가 결정되게 된다
- 프로듀서에 따로 파티셔너를 설정하지 않았으면 UniformStickyPartitioner로 설정이된다
- 메시지 키가 있을 때 와 없을때 다르게 동작한다
- 있는경우 파티셔너에 의해서 키를가지고 해시값이 생성되게 된다 이 값을 가지고 어느 파티션에 들어갈지 결정되게 된다
- 여기서 파티션이 중간에 추가되는경우 키 <-> 파티션의 일관성이 보장되지 않기 때문에 뒤죽박죽 될 수 있다 그렇기 때문에 키를 사용한다면 파티션을 중간에 추가하는건 고려를 많이 해봐야한다.
- 없는경우 라운드 로빈 방식으로 돌아간다. 파티셔너가 모을수 있는 최대한의 데이터를 최대한 모아서 보낸다(배치방식)(파티션에 적절히 보낸다고 생각하면된다.)
- 있는경우 파티셔너에 의해서 키를가지고 해시값이 생성되게 된다 이 값을 가지고 어느 파티션에 들어갈지 결정되게 된다
- 메시지 키가 있을 때 와 없을때 다르게 동작한다

- 카프카 컨슈머 Lag 이란?
- 오프셋
- 프로듀서는 토픽에 파티션에 데이터를 넣게된다 각 데이터에 붙는 번호가 오프셋이다
- 데이터를 어디까지 읽었는지 확인하는 용도로 활용된다
- 프로듀서가 데이터를 넣는 속도가 컨슈머가 데이터를 가져가는 속도보다 높게 된다면?
- 그러면 프로듀서가 마지막으로 넣은 오프셋 컨슈머가 마지막으로 가져간 오프셋의 차이가 발생한다 이것이 바로 컨슈머 Lag이다
- 이것으로 프로듀서와 컨슈머의 상태에 대해 체크가 가능하다
- 파티션이 여러개 존재할 경우 Lag은 여러개 존재할 수 있다
- 오프셋
- Burrow(카프카 컨슈머 Lag을 모니터링을 도와주는 독립적인 애플리케이션)
- 특징
- 멀티 카프카 클러스터 지원
- 클러스터가 여러개라도 한번에 lag을 모니터링 가능
- 슬라이딩 왼도우를 이용한 컨슈머의 상태를 쉽게 확인가능
- HTTP API 제공
- 확정성이 좋다
- 멀티 카프카 클러스터 지원
- 특징
- 카프카, MQ, 캐시서버 의 차이
- 메시지 브로커
- 메시지를 받아서 처리하고 나면 메시지는 삭제된다
- 이벤트 브로커
- 이벤트 또는 메시지라고도 불리는 레코드를 딱 하나만 보관하고 인덱스를 통해 개별 엑세스를 관리
- 업무상 필요한 시간동안 이벤트를 보존할 수 있다
- 데이터가 살아있기 때문에 장애시 특정 시점부터 복구 가능
- 데이터가 살아있기 때문에 MSA에서도 유용하게 쓰인다
- 기타 확장성이 좋다
- 메시지 브로커
- 주키퍼
- 카프카 관련 정보를 저장하는 역할을 한다
- 프로듀서
- 데이터를 토픽안에 파티션에 프로듀싱 즉 생산하는 역할을한다
- 전송 성공여부를 알 수 있고 재시도도 할 수 있다
- 컨슈머
- 데이터를 컨슈밍 즉 토픽안에 파티션에서 데이터를 가져오는 역할을한다
- 오프셋 위치를 커밋 할 수 있다
- 컨슈머가 여러개일 경우 병렬처리 할 수 있다
- 컨슈머 그룹 아이디를 지정해 컨슈머의 그룹을 만들수 있다
- 컨슈머가 데이터를 읽기 시작하면 오프셋을 커밋하게 되는데 이 내용을 카프카 컨슈머 오프셋 토픽에 저장한다
- 컨슈머가 장애가 있을경우 어디서부터 읽어야 할지 모른다면 카프카 컨슈머 오프셋 토픽에 어디까지 읽었는지 알고 있으므로 복구 가능하다
- 컨슈머 오프셋 토픽은 컨슈머 그룹별로 따로 관리하기 때문에 서로 다른 컨슈머 그룹에서 같은 토픽 파티션에 접근 가능하다
- 하나의 토픽에 여러 컨슈머가 있는경우
- 파티션과 같은 그룹의 컨슈머는 1:1 매칭됨으로 반드시 컨슈머의 개수는 파티션의 개수보다 적거나 같아야한다
- 파티션과 서로 다른 그룹의 컨슈머는 동일한 토픽의 파티션에서 데이터를 가져 올 수 있따


- 카프카 스트림즈
- 카프카에서 공식적으로 제공하는 자바 라이브러리
- 토픽에 있는 데이터를 낮은 지연과 함께 빠르게 처리 가능하다
- 카프카 커넥트
- 카프카 데이터 파이프라인을 편하게 만들어주는 어플리케이션
출처 : 유튜브 데브원영
Comments